RDD的设计与运行原理
Spark的核心是建立在统一的抽象RDD(Resilient Distributed Datasets)之上,使得Spark的各个组件可以无缝进行集成,在同一个应用程序中完成大数据计算任务。RDD的设计理念源自AMP实验室发表的论文《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》。
- RDD设计背景
在实际应用中,存在许多迭代式算法(比如机器学习、图算法等)和交互式数据挖掘工具,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,目前的MapReduce框架都是把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘IO和序列化开销。
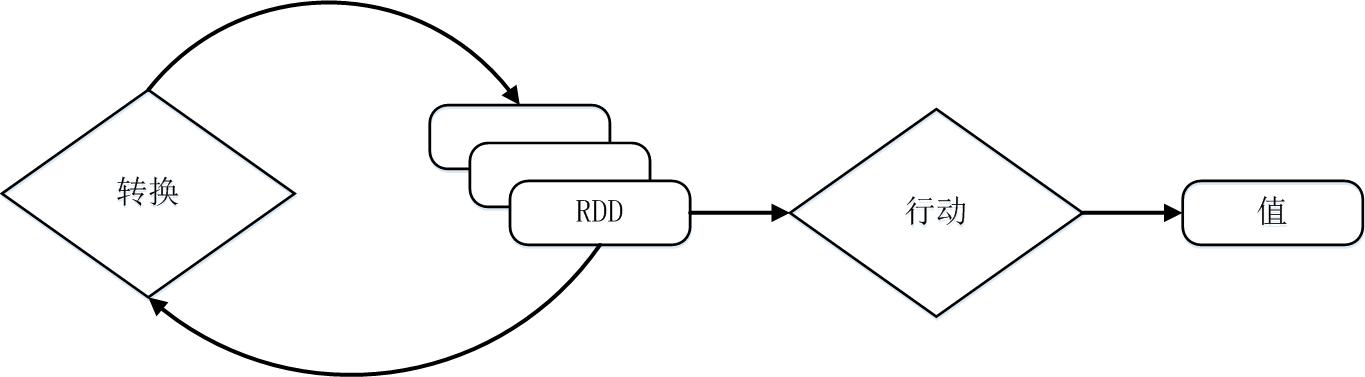
- RDD概念 RDD提供了一组丰富的操作以支持常见的数据运算,分为Transformation(指定RDD之间的相互依赖关系)和Action(用于执行计算并指定输出的形式)两种类型。两类操作的主要区别是,转换操作(比如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。
需要说明的是,RDD采用了惰性调用,即在RDD的执行过程中(如图9-8所示),真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。
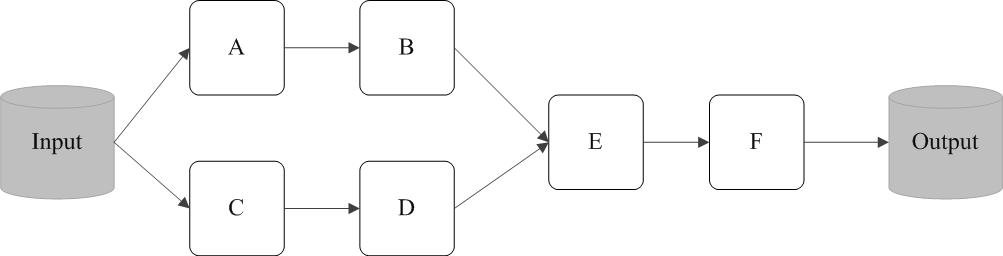
例如,下图中,从输入中逻辑上生成A和C两个RDD,经过一系列“转换”操作,逻辑上生成了F(也是一个RDD),之所以说是逻辑上,是因为这时候计算并没有发生,Spark只是记录了RDD之间的生成和依赖关系。当F要进行输出时,也就是当F进行“行动”操作的时候,Spark才会根据RDD的依赖关系生成DAG,并从起点开始真正的计算。
启动pyspark
1
PYSPARK_PYTHON=python3 ./bin/pyspark
在pyspark的交互环境下,输入如下代码
1
2
3
4
5
6
fileRDD = sc.textFile('hdfs://localhost:9000/test.txt')
def contains(line):
... return 'hello world' in line
filterRDD = fileRDD.filter(contains)
filterRDD.cache()
filterRDD.count()
可以看出,一个Spark应用程序,基本是基于RDD的一系列计算操作。第1行代码从HDFS文件中读取数据创建一个RDD;第2、3行定义一个过滤函数;第4行代码对fileRDD进行转换操作得到一个新的RDD,即filterRDD;第5行代码表示对filterRDD进行持久化,把它保存在内存或磁盘中(这里采用cache接口把数据集保存在内存中),方便后续重复使用,当数据被反复访问时(比如查询一些热点数据,或者运行迭代算法),这是非常有用的,而且通过cache()可以缓存非常大的数据集,支持跨越几十甚至上百个节点;第5行代码中的count()是一个行动操作,用于计算一个RDD集合中包含的元素个数。这个程序的执行过程如下:
- 创建这个Spark程序的执行上下文,即创建SparkContext对象;
- 从外部数据源(即HDFS文件)中读取数据创建fileRDD对象;
- 构建起fileRDD和filterRDD之间的依赖关系,形成DAG图,这时候并没有发生真正的计算,只是记录转换的轨迹;
- 执行到第6行代码时,count()是一个行动类型的操作,触发真正的计算,开始实际执行从fileRDD到filterRDD的转换操作,并把结果持久化到内存中,最后计算出filterRDD中包含的元素个数。
- RDD特性
跳过
- RDD之间的依赖关系
- 阶段的划分
- RDD运行过程
以上模模糊糊懂,但对运行也无甚帮助。